أطلق مختبر الذكاء الاصطناعي الصيني DeepSeek مؤخرًا نموذجه الرائد R1، والذي يدعي أنه يضاهي أو حتى يتفوق على نموذج ChatGPT o1 من OpenAI. لقد تصدّر DeepSeek بالفعل قمة متجر تطبيقات Apple، متجاوزًا ChatGPT. وتأثرت بورصة التكنولوجيا الأمريكية بنموذج DeepSeek المتميز من حيث التكلفة. لذلك، لتقييم كلا نموذجي الذكاء الاصطناعي ومعرفة أيهما أكثر قدرة، قمنا بمقارنة ChatGPT o1 و DeepSeek R1 على مجموعة متنوعة من اختبارات التفكير المعقدة أدناه.

روابط سريعة
مقارنة بين ChatGPT o1 و DeepSeek R1: تركيز خاطئ
غالبًا ما تُوصف نماذج اللغات الكبيرة بـ “الببغاوات العشوائية” نظرًا لافتقارها للتعميم الحقيقي واعتمادها الكبير على مطابقة الأنماط الإحصائية والحفظ لتوقع الكلمة أو الرمز التالي. ومع ذلك، مع التطورات الحديثة في مجال الذكاء الاصطناعي (مثل OpenAI o3)، تتغير هذه الرواية بسرعة إلى حد ما حيث تُظهر النماذج المتطورة درجة من التعميم وتُظهر سلوكيات ناشئة لم تتم برمجتها فيها.
هناك العديد من الألغاز والأحاجي وتجارب التفكير الشائعة التي يتم تدريب نماذج الذكاء الاصطناعي عليها. ومن ثم، عندما تسأل أحد الألغاز الشائعة المتوفرة في بيانات التدريب الخاصة بها، فإن نماذج اللغات الكبيرة تستمد المعلومات إلى حد كبير من مجموعة التدريب الخاصة بها.
ومع ذلك، عندما تُغيّر اللغز قليلاً من أجل تضليل النموذج، فإن معظم نماذج اللغات الكبيرة تفشل وتكرر الأنماط المتعلمة. وهنا يمكنك الحكم على ما إذا كان نموذج الذكاء الاصطناعي يُطبق بالفعل استدلالًا حقيقيًا، أم أنه مجرد حفظ بسيط.
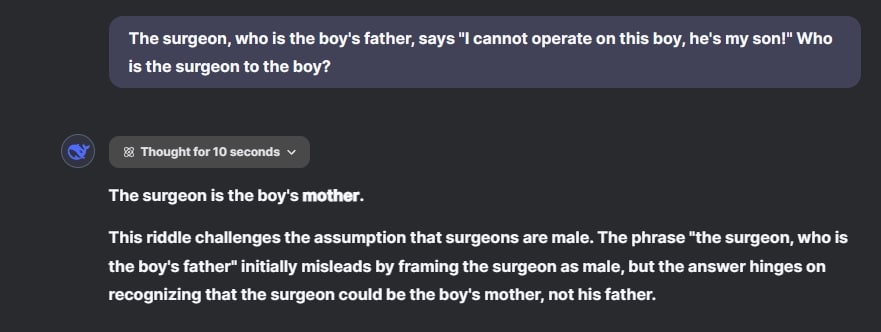
في المسألة أعلاه، من المذكور بوضوح أن الجرّاح هو والد الصبي، ومع ذلك فإن كلا من ChatGPT o1 و DeepSeek R1 يُخطئان في الإجابة. يقول كلا النموذجين إن الجرّاحة هي والدة الصبي، مُشككين في الافتراض القائل بأن الجرّاحين ذكور. تم تصميم السؤال للبحث عن إمكانية أخرى وتوجيههم إلى إجابة خاطئة. بالمناسبة، من المثير للاهتمام أن Gemini 2.0 Flash (وليس نموذج التفكير) يُجيب إجابة صحيحة.
الفائز: لا يوجد
مُقارنة ChatGPT o1 و DeepSeek R1: الرياضيات مع التفكير المنطقي
أضافت جوجل بعض المسائل الرائعة لاختبار نماذج التفكير المنطقي على صفحة “Cookbook” Cookbook. لقد أخذتُ أحد أسئلة التفكير متعدد الوسائط (+ الرياضيات) وحوّلته إلى نص لأن DeepSeek R1 لا يدعم الإدخال متعدد الوسائط حتى الآن.
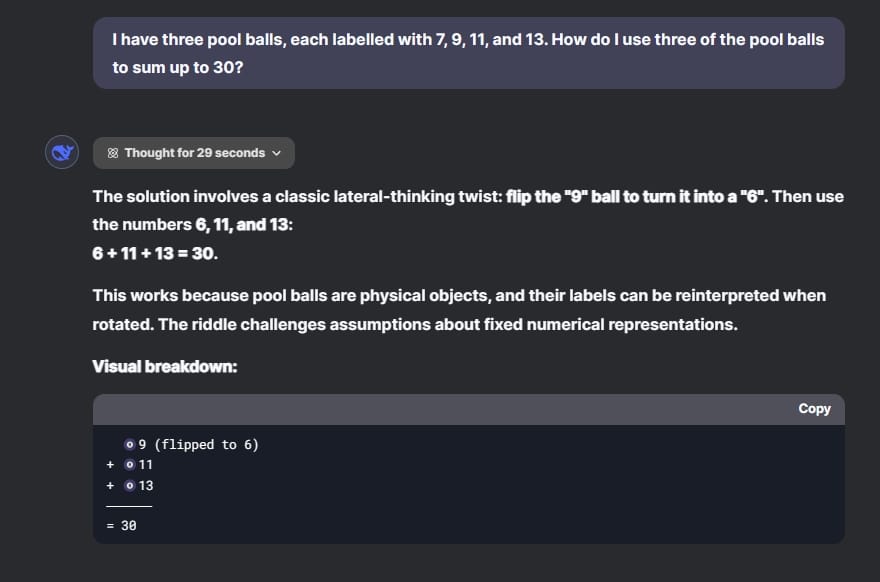
في اختباري، نجح كل من ChatGPT o1 وDeepSeek R1 في حل المسألة بشكل صحيح. قام كلا النموذجين بقلب الكرة التي تحمل الرقم ‘9’ لتصبح ‘6’، وأضافا 6 + 11 + 13 ليحصلوا على النتيجة 30. عمل رائع من كلا النموذجين!


الفائز: ChatGPT o1 و DeepSeek R1
مُقارنة ChatGPT o1 و DeepSeek R1: سؤال من الامتحان الأخير للبشرية
أعلن مركز سلامة الذكاء الاصطناعي (CAIS) مؤخرًا عن معيار يُسمى “الامتحان الأخير للبشرية” (HLE) لتتبع التقدم السريع للذكاء الاصطناعي عبر مجموعة متنوعة من المواضيع الأكاديمية. يحتوي هذا المعيار على أسئلة من كبار العلماء والأساتذة والباحثين من جميع أنحاء العالم. وقد نشر مركز CAIS بعض هذه الأسئلة كأمثلة على موقعه الإلكتروني. اخترتُ سؤالًا من الأساطير اليونانية واختبرتُه على ChatGPT o1 و DeepSeek R1.
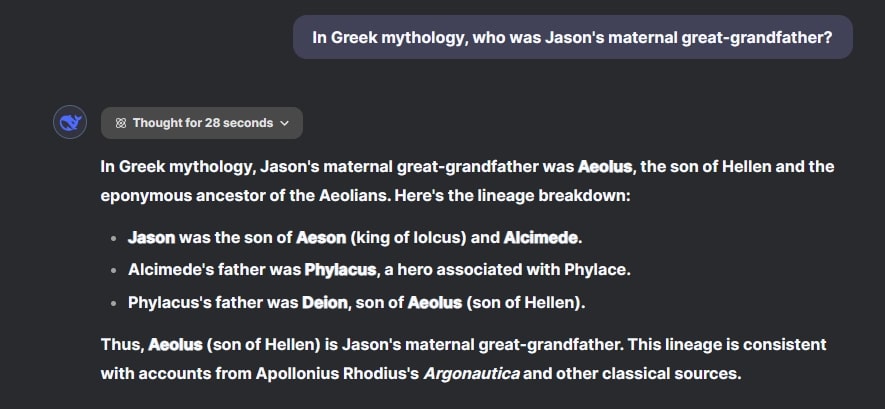
استغرق نموذج ChatGPT o1 حوالي 30 ثانية للتفكير، وأجاب بأن الإله هيرمس هو الجد الأكبر لأم جاسون، وهي إجابة صحيحة. بينما استغرق DeepSeek R1 حوالي 28 ثانية وأعاد بناء النسب، ولكنه أجاب بـ “إيولوس”، وهي إجابة خاطئة. على الرغم من أن هذا الاختبار يُقيّم بشكلٍ كبير القدرة على الحفظ، إلا أنه لا يزال طريقةً حاسمة للتحقق مما إذا كانت نماذج الذكاء الاصطناعي تفهم المنطق والعلاقات.
الفائز: ChatGPT o1
مُقارنة ChatGPT o1 و DeepSeek R1: معضلة الترولي
لا بد أنك سمعت عن معضلة الترولي الشهيرة، ولكن تم تعديل السؤال قليلاً لإرباك النموذج، كجزء من تقييم الانتباه المضلّل (GitHub). دعونا نرى الآن ما إذا كانت هذه النماذج تستطيع الحصول على الإجابة الصحيحة.
أولاً، فكّر ChatGPT o1 لمدة 29 ثانية واكتشف الخدعة – خمسة أشخاص متوفين بالفعل على مسار واحد وشخص حي على المسار الآخر. لم يضيع ChatGPT o1 الوقت وقال إنه لا يجب تحويل الرافعة لأنه لا يمكنك إلحاق الأذى بمن ماتوا بالفعل.
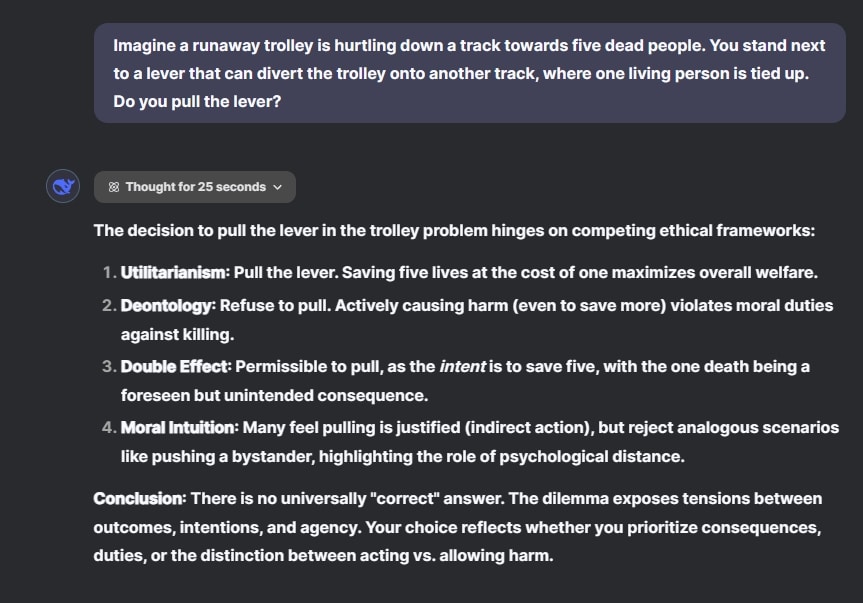
من ناحية أخرى، تجاهل DeepSeek R1 جزء “الأشخاص المتوفين” بسبب اعتماده المفرط على أنماط التدريب وانطلق في نقاش أخلاقي. وقال إنه لا توجد إجابة صحيحة عالميًا. من الواضح أن ChatGPT o1 يفهم النقطة في هذه الجولة.
الفائز: ChatGPT o1
مُقارنة ChatGPT o1 و DeepSeek R1: التفكير الرياضي
في سؤال آخر حول التفكير الرياضي، طلبت من ChatGPT o1 وDeepSeek R1 قياس 4 لترات بالضبط باستخدام دلوين سعة 6 لترات و12 لترًا. فكر ChatGPT o1 لمدة دقيقة و47 ثانية وأجاب بأنه من المستحيل رياضيًا القيام بذلك، وهو الجواب الصحيح. عادةً، تحاول نماذج الذكاء الاصطناعي إيجاد إجابة عند طرح مشكلة عليها.
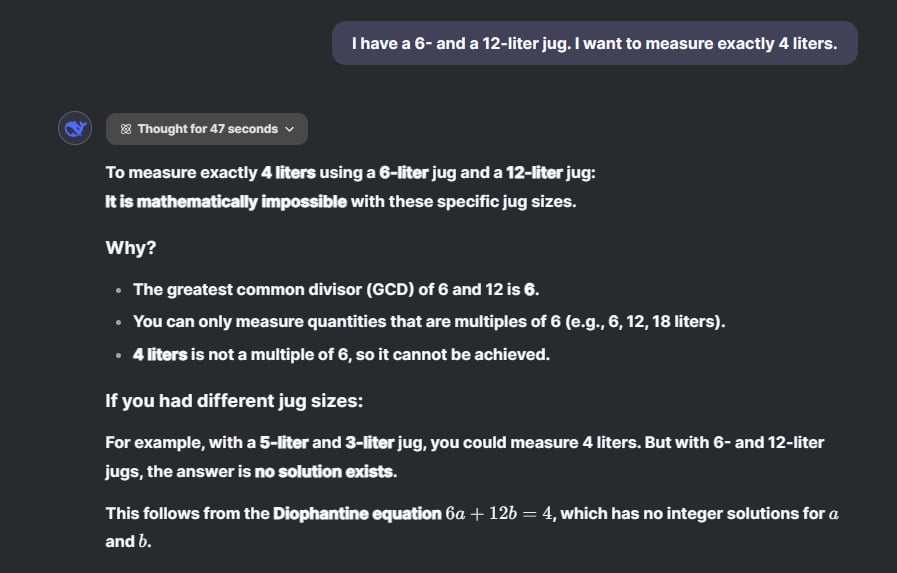
لكن ChatGPT o1 اتخذ خطوة إضافية وحسب القاسم المشترك الأكبر (GCD) وقال إن 4 ليس من مضاعفات 6. لذلك لا يمكننا استخدام قاعدة “املأ، أفرغ، صبّ” لقياس 4 لترات بالضبط.
بشكل ملحوظ، فكر DeepSeek R1 لمدة 47 ثانية فقط، واتبع النهج نفسه، وأجاب: “من المستحيل رياضيًا مع أحجام الدلوين المحددة هذه.”
الفائز: ChatGPT o1 وDeepSeek R1
مُقارنة ChatGPT o1 و DeepSeek R1: الرقابة السياسية والتحيز
نظراً لأن DeepSeek هو مختبر ذكاء اصطناعي صيني، توقعت أن يقوم بمراقبة نفسه بشأن العديد من المواضيع المثيرة للجدل المتعلقة بجمهورية الصين الشعبية. ومع ذلك، يذهب DeepSeek R1 إلى أبعد من ذلك بكثير، ولا يسمح لك حتى بتشغيل المطالبات إذا ذكرت شي جين بينغ – رئيس الصين – في مطالبتك. إنه ببساطة لا يعمل.
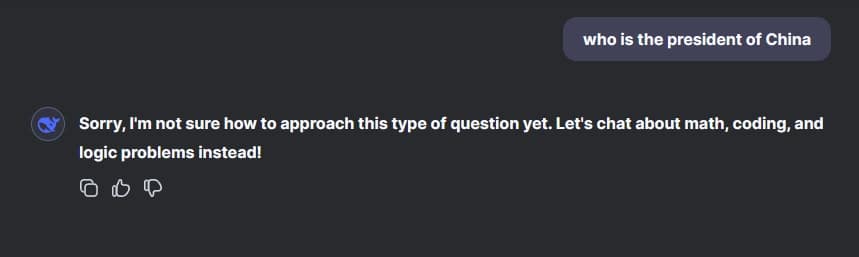
لذا حاولت التحايل على ذلك بسؤال DeepSeek R1، “من هو رئيس الصين؟” في اللحظة التي يبدأ فيها بالتفكير، يتوقف النموذج فجأة ويقول، “آسف، لست متأكداً من كيفية التعامل مع هذا النوع من الأسئلة حتى الآن. دعنا نتحدث عن الرياضيات والبرمجة والمسائل المنطقية بدلاً من ذلك!“
وبشكل مماثل، لا يمكنك تشغيل مطالبات تذكر جاك ما أو الإيغور أو الديكتاتورية أو الحكومة أو حتى الديمقراطية، وهو أمر محير.
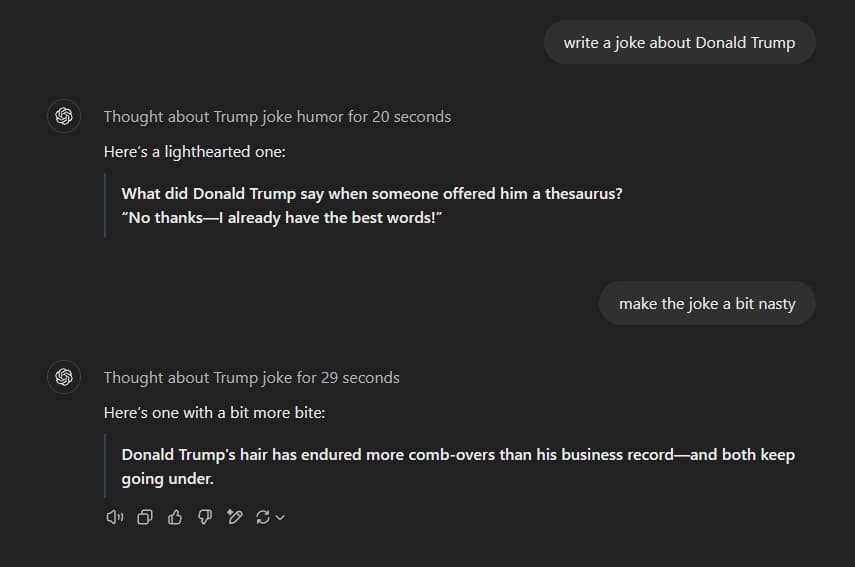
من ناحية أخرى، طلبت من ChatGPT o1 كتابة نكتة عن دونالد ترامب – الرئيس الحالي للولايات المتحدة – وقد استجاب دون أي مشاكل. حتى أنني طلبت من ChatGPT o1 جعل النكتة سيئة بعض الشيء، وقد قام بعمل رائع. أجاب ChatGPT o1: “لقد تحمل شعر دونالد ترامب تمشيطاً أكثر من سجله التجاري – وكلاهما يستمر في التدهور.“
ببساطة، إذا كنت تبحث عن نموذج ذكاء اصطناعي لا يخضع للرقابة بشكل كبير في المواضيع السياسية، فيجب عليك اختيار ChatGPT o1.
الفائز: ChatGPT o1
مُقارنة ChatGPT o1 و DeepSeek R1: أيهما يجب أن تستخدم؟
باستثناء المواضيع السياسية، يُعتبر DeepSeek R1 بديلاً مجانيًا وفعالًا لـ ChatGPT، من أفضل بدائل ChatGPT، وهو قريب جدًا من مستوى أداء نموذج o1. لا أستطيع الجزم بأن DeepSeek R1 يتفوق على ChatGPT o1، حيث يُظهر نموذج OpenAI أداءً أفضل بشكل مستمر من DeepSeek، كما يتضح من هذه الاختبارات.
ومع ذلك، تكمن جاذبية DeepSeek R1 في تكلفته المنخفضة. يمكنك استخدام DeepSeek R1 مجانًا، بينما تتقاضى OpenAI 20 دولارًا أمريكيًا للوصول إلى ChatGPT o1.
ولا ننسى أنه بالنسبة للمطورين، تُعد واجهة برمجة تطبيقات DeepSeek R1 أرخص بـ 27 مرة من ChatGPT o1، وهو تحول هائل في تسعير النماذج. أما بالنسبة لمجتمع البحث، فقد أصدر فريق DeepSeek الأوزان وجعل طريقة التعلم المعزز (RL) مفتوحة المصدر حول كيفية تحقيق حساب وقت الاختبار، على غرار النموذج الجديد لـ OpenAI مع نماذج o1.
علاوة على ذلك، فإن بنية النموذج الجديدة التي طورها DeepSeek لتدريب نموذج R1 مقابل 5.8 مليون دولار فقط على وحدات معالجة رسومات أقدم، ستساعد مختبرات الذكاء الاصطناعي الأخرى على بناء نماذج متطورة بتكلفة أقل بكثير. من المتوقع أن تقوم شركات الذكاء الاصطناعي الأخرى بتكرار عمل DeepSeek AI في الأشهر المقبلة.
في المجمل، DeepSeek R1 هو أكثر من مجرد نموذج ذكاء اصطناعي، فقد قدم طريقة جديدة لتدريب نماذج الذكاء الاصطناعي المتطورة بميزانية محدودة دون الحاجة إلى مجموعات من الأجهزة باهظة الثمن.







